

Stop errors from null SQL values
In Power Automate

The SQL Server connector and associated actions in Power Automate has an interesting quirk where it does not return any columns for a record(s) if the column value is NULL.
This can cause issues if you’re trying to use a particular column for comparison purposes or simply to use downstream in another action of your flow.
Note, this may not be limited to the SQL Server connector but that is the only place I’ve personally run into it so far.
Thankfully, there is an easy fix to this - use the coalesce() function.
Example Scenario
Let’s say we have a table called Approvals with the following columns - ID, Description, Status, MgrOverrideCount, and CompletedDate.
In our flow we want to evaluate if this Approval has already been through at least one Manager Override cycle.
Our first step is to use a SQL Get row (V2) action to retrieve our desired row. Once we have that we’ll use a Condition to check the value of the MgrOverrideCount (int) field and then update a variable with this value.
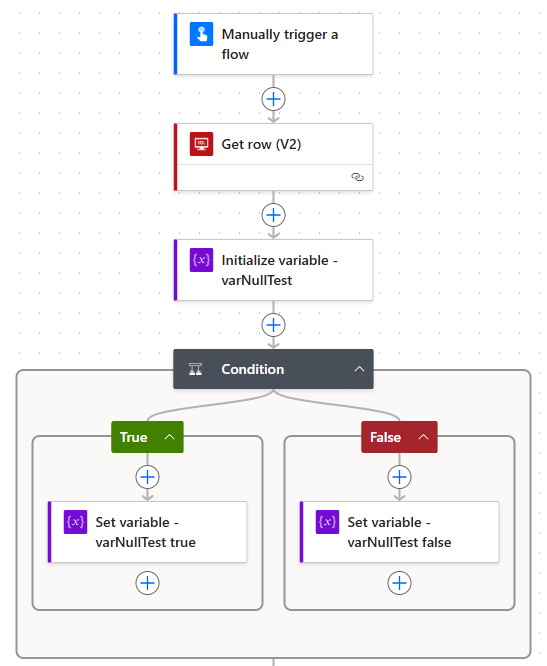
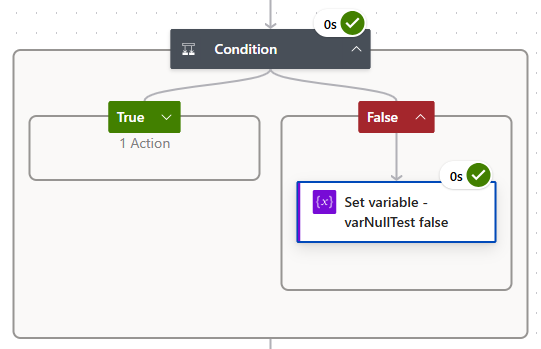
Here is what our Condition and Set variable actions would probably look like on the first attempt, using dynamic data from our previous action -



When we run this against a known record with a NULL MgrOverrideCount value we will get one explicit error and one unwanted behavior (IMO).
Before we get to the errors though, let’s look at what exactly the SQL Get row action returned to us.
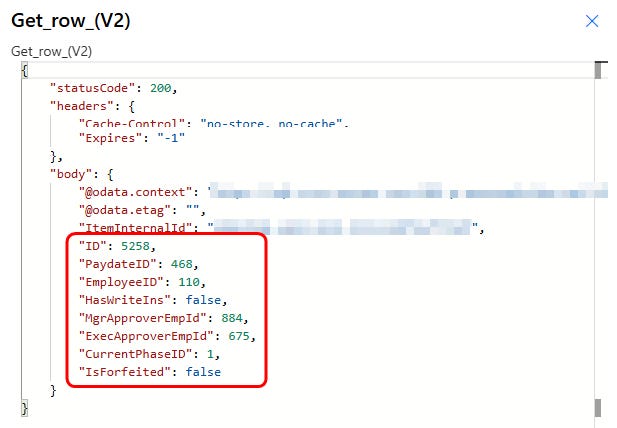
Notice that our MgrOverrideCount field doesn’t show up at all. For better or for worse this seems to be how Power Automate handles NULL fields. It isn’t that the field/column doesn’t exist, we know it is in our table, but probably in the name of efficiency or something like that, the SQL Get row action just leaves out all of the NULL value fields/columns. In fact, there are a total of six NULL value columns for this particular record that have been left out of the output body of this SQL Get row action.
Okay, now back to our errors….
First, the unwanted behavior, our condition will evaluate without throwing an error and will return NULL > 0 = false. Personally, I don’t like this behavior, and I think this should return an error since NULL is not an integer value. But this is the way Power Automate currently handles this scenario, so we’ve got to deal with it.
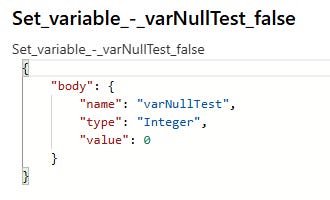
Thankfully, our Set variable - varNullTest false action will throw an actual error since we defined this variable as an Integer type upon initialization; and now suddenly Power Automate is smart enough to realize NULL is not an integer and yells at us.

Solution
To work around these odd issues - SQL actions not returning null columns and Conditions not erroring out on NULL vs integer (or any other data types) - we’re going to use the aforementioned Coalesce function in two places.
In this first case, we’re going to use it in the Condition statement. Not because we have to, technically in this example we could probably safely accept NULL > 0 = false - but I don’t like it. So, in place of the raw dynamic data from the previous Get row action, we’re going to combine that dynamic data inside a Coalesce function like this -
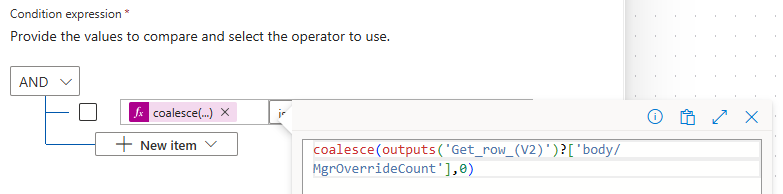
coalesce(outputs('Get_row_(V2)')?['body/MgrOverrideCount'],0)Now when the MgrOverrideCount field is not returned at all by our SQL Get row action, coalesce will substitute a zero in its place. Again, this isn’t strictly required for our particular Condition, since 0 > 0 = false is the same result as NULL > 0 = false but I can rest a little easier knowing at least we’re comparing an integer against an integer to get our result.
The second, and most important, place we’re going to use this exact same coalesce function is in the False leg of our Condition and the Set variable - varNullTest false action.
This is the step that truly errored-out on us before, so we’ll again replace the dynamic data for the MgrOverrideCount with the same above coalesce function.
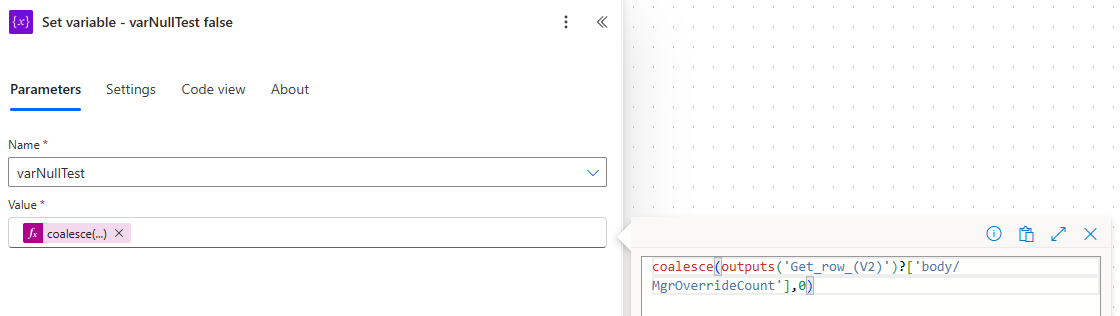
And just like that, we have a working solution!
Of course, if your particular field is not an integer, you can adapt all of this by using ‘‘ (two single quotes) for String or Date based fields to represent an empty value, and so on.